Frequentist and Bayesian Methods#
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
import pandas as pd
import scipy.stats
Types of Probability#
We construct a probability space by assigning a numerical probability in the range \([0,1]\) to sets of outcomes (events) in some space.
When outcomes are the result of an uncertain but repeatable process, probabilities can always be measured to arbitrary accuracy by simply observing many repetitions of the process and calculating the frequency at which each event occurs.
The frequentist interpretation of probability is the long-run frequency of repeatable experiments. For example, saying that the probability of a coin landing heads being 0.5 means that if we were to flip the coin enough times, we would see heads 50% of the time.
These frequentist probabilities have an appealing objective reality to them. However, you cannot define a probability for events that are not repeatable. For instance, before the 2018 FIFA world cup, let’s say that you read somewhere that Brazil’s probability of winning the tournament was 14%. This probability cannot really be explained with a purely frequentist interpretation, because the experiment is not repeatable! The 2018 world cup is only going to happen once, and it’s impossible to repeat the exact experiment with the same exact conditions, players and preceding events.
DISCUSS: How might you assign a frequentist probability to statements like:
The electron spin is 1/2.
The Higgs boson mass is between 124 and 126 GeV.
The fraction of dark energy in the universe today is between 68% and 70%.
The superconductor \(\text{Hg}\text{Ba}_2\text{Ca}_2\text{Cu}_3\text{O}_{8+δ}\) (Hg-1223) has a critical temperature above \(130 K\).
You cannot (if we assume that these are universal constants), since that would require a measurable process whose outcomes had different values for a universal constant.
The inevitable conclusion is that the statements we are most interested in cannot be assigned frequentist probabilities.
However, if we allow probabilities to also measure your subjective “degree of belief” in a statement, then we can use the full machinery of probability theory to discuss more interesting statements. These are called Bayesian probabiilities.
As usual, an XKCD comic captures the essence of the situation:

This is sort and absurd example, but this gets right to the core of the potential issues with frequentist inference. The chance of the sun exploding spontaneously are so low given well-known stellar and gravitational physics that it is far more likely that the two die both came up a 6 than that it is that the sun actually exploded.
Since Frequentist inference does not take the probability of the sun exploding into account (the only data that matters is the die roll), taking a purely Frequentist approach can run into problems like these. And while it may be easy to spot the issue here, in contexts like scientific research it can be much harder to identify that this may be happening in your experiment.
In other words, frequentist statistics estimates the desired confidence percentage (usually 95%) in which some parameter is placed. In contrast, Bayesian analysis answers the following question: “What is the probability of the hypothesis (model) given the measured data?” In addition, frequentist statistics accepts or rejects the null hypotheses, but Bayesian statistics estimates the ratio of probabilities of two different hypotheses. This ratio is known as the Bayes factor that we will study soon. The Bayes factor quantifies the support for one hypothesis over another, irregardless of whether either of these hypotheses are correct.
Roughly speaking, the choice is between:
Frequentist statistics: objective probabilities of uninteresting statements.
Bayesian statistics: subjective probabilities of interesting statements.
Bayesian Joint Probability#
Bayesian statistics starts from a joint probability distribution
over
data features \(D\)
model parameters \(\Theta_M\)
hyperparameters \(M\)
The subscript on \(\Theta_M\) is to remind us that, in general, the set of parameters being used depends on the hyperparameters (e.g., increasing n_components adds parameters for the new components). We will sometimes refer to the pair \((\Theta_M, M)\) as the model.
This joint probability implies that model parameters and hyperparameters are random variables, which in turn means that they label possible outcomes in our underlying probability space.
For a concrete example, consider the possible outcomes necessary to discuss the statement “the electron spin is 1/2”, which must be labeled by the following random variables:
\(D\): the measured electron spin for an outcome, \(S_z = 0, \pm 1/2, \pm 1, \pm 3/2, \ldots\)
\(\Theta_M\): the total electron spin for an outcome, \(S = 0, 1/2, 1, 3/2, \ldots\)
\(M\): whether the electron is a boson or a fermion for an outcome.
A table of random-variable values for possible outcomes would then look like:
\(M\) |
\(\Theta_M\) |
\(D\) |
|---|---|---|
boson |
0 |
0 |
fermion |
1/2 |
-1/2 |
fermion |
1/2 |
+1/2 |
boson |
1 |
-1 |
boson |
1 |
0 |
boson |
1 |
+1 |
… |
… |
… |
Only two of these outcomes occur in our universe, but a Bayesian approach requires us to broaden the sample space from “all possible outcomes” to “all possible outcomes in all possible universes”.
Likelihood#
The likelihood \({\cal L}_M(\Theta_M, D)\) is a function of model parameters \(\Theta_M\) (given hyperparameters \(M\)) and data features \(D\), and measures the probability (density) of observing the data \(\vec{x}\) given the model. For example, a Gaussian mixture model has the likelihood function:
with parameters
and hyperparameter \(K\). Note that the likelihood must be normalized over the data for any values of the (fixed) parameters and hyperparameters. However, it is not normalized over the parameters or hyperparameters.
The likelihood function plays a central role in both frequentist and Bayesian statistics, but is used and interpreted differently. We will focus on the Bayesian perspective, where \(\Theta_M\) and \(M\) are considered random variables and the likelihood function is associated with the conditional probability
of observing features \(D\) given the model \((\Theta_M, M)\).
Bayesian Inference#
The term “Bayesian inference” comes from Bayes’ Theorem, which in turn is named after Thomas Bayes, an English statistician from the 18th century. In fact, the key ideas behind Bayes’ theorem were also used independently by the French mathematician Pierre-Simon Laplace around the same time.
Once we associated the likelihood with a conditional probability, we can apply the earlier rules (2 & 3) of probability calculus to derive the Generalized Bayes’ Rule:
Each term above has a name and measures a different probability:
Posterior: \(P(\Theta_M\mid D, M)\) is the probability of the parameter values \(\Theta_M\) given the data and the choice of hyperparameters.
Likelihood: \(P(D\mid \Theta_M, M)\) is the probability of the data given the model.
Prior: \(P(\Theta_M\mid M)\) is the probability of the model parameters given the hyperparameters and marginalized over all possible data.
Evidence: \(P(D\mid M)\) is the probability of the data given the hyperparameters and marginalized over all possible parameter values given the hyperparameters.
In typical inference problems, the posterior (1) is what we really care about and the likelihood (2) is what we know how to calculate. The prior (3) is where we must quantify our subjective “degree of belief” in different possible universes.
What about the evidence (4)? Using the earlier rule (5) of probability calculus (near the bottom of this notebook), we discover that (4) can be calculated from (2) and (3):
Note that this result is not surprising since the denominator must normalize the ratio to yield a probability (density). When the set of possible parameter values is discrete, \(\Theta_M \in \{ \Theta_{M,1}, \Theta_{M,2}, \ldots\}\), the normalization integral reduces to a sum:
The generalized Bayes’ rule above assumes fixed values of any hyperparameters (since \(M\) is on the RHS of all 4 terms), but a complete inference also requires us to consider different hyperparameter settings. We will defer this (harder) model selection problem until later.

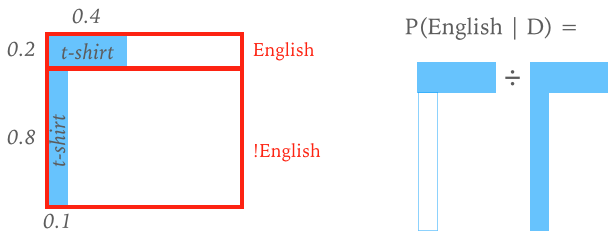
EXERCISE: Suppose that you meet someone for the first time at your next conference and they are wearing an “England” t-shirt. Estimate the probability that they are English by:
Defining the data \(D\) and model \(\Theta_M\) assuming, for simplicity, that there are no hyperparameters.
Assigning the relevant likelihoods and prior probabilities (terms 2 and 3 above).
Calculating the resulting LHS of the generalized Baye’s rule above.
Solution:
Define the data \(D\) as the observation that the person is wearing an “England” t-shirt.
Define the model to have a single parameter, the person’s nationality \(\Theta \in \{ \text{English}, \text{!English}\}\).
We don’t need to specify a full likelihood function over all possible data since we only have a single datum. Instead, it is sufficient to assign the likelihood probabilities:
Note that the likelihood probabilities do not sum to one since the likelihood is normalized over the data, not the model, unlike the prior probabilities which must sum to one.
Assign the prior probabilities for attendees at the conference:
We can now calculate the LHS of the generalized Bayes’ rule which gives an estimate of the probabilty that the person is English given the shirt (Note: we calculate the evidence \(P(D)\) using a sum rather than integral, because \(\Theta\) is discrete.):
You would have probably assigned different probabilities, since these are subjective assessments where reasonable people can disagree. However, by allowing some subjectivity we are able to make a precise statement under some (subjective) assumptions.
A simple example like this can be represented graphically in the 2D space of joint probability \(P(D, \Theta)\):
The generalized Bayes’ rule can be viewed as a learning rule that updates our knowledge as new information becomes available:
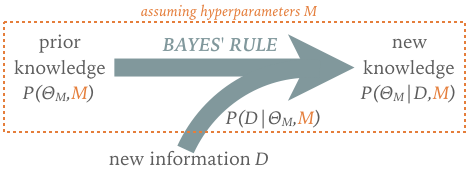
The generalized Bayes’ rule can be viewed as a learning rule that updates our knowledge as new information becomes available:
The implied timeline motivates the posterior and prior terminology, although there is no requirement that the prior be based on data collected before the “new” data.
Bayesian inference problems can be tricky to get right, even when they sound straightforward, so it is important to clearly spell out what you know or assume, and what you wish to learn:
List the possible models, i.e., your hypotheses.
Assign a prior probability to each model.
Define the likelihood of each possible observation \(D\) for each model.
Apply Bayes’ rule to learn from new data and update your prior.
For problems with a finite number of possible models and observations, the calculations required are simple arithmetic but quickly get cumbersome. A helper function lets you hide the arithmetic and focus on the logic:
def learn(prior, likelihood, D):
# Calculate the Bayes' rule numerator for each model.
prob = {M: prior[M] * likelihood(D, M) for M in prior}
# Calculate the Bayes' rule denominator.
norm = sum(prob.values())
# Return the posterior probabilities for each model.
return {M: prob[M] / norm for M in prob}
For example, the problem above becomes:
prior = {'English': 0.2, '!English': 0.8}
def likelihood(D, M):
if M == 'English':
return 0.4 if D == 't-shirt' else 0.6
else:
return 0.1 if D == 't-shirt' else 0.9
learn(prior, likelihood, D='t-shirt')
Note that the (posterior) output from one learning update can be the (prior) input to the next update. For example, how should we update our knowledge if the person wears an “England” t-shirt the next day also? (What might we think if the person wears an “England” t-shirt for a third day and we notice it’s always the same shirt…)
post1 = learn(prior, likelihood, 't-shirt')
post2 = learn(post1, likelihood, 't-shirt')
#post3 = learn(post2, likelihood, 't-shirt')
print(post2)
Below is a helper function Learn for these calculations that allows multiple updates with one call and displays the learning process as a pandas table:
import IPython.display
def Learn(prior, likelihood, *data):
"""Learn from data using Bayesian inference.
Assumes that the model and data spaces are discrete.
Parameters
----------
prior : dict
Dictionary of prior probabilities for all possible models.
likelihood : callable
Called with args (D,M) and must return a normalized likelihood.
data : variable-length list
Zero or more items of data to use in updating the prior.
"""
# Initialize the Bayes' rule numerator for each model.
prob = prior.copy()
history = [('PRIOR', prior)]
# Loop over data.
for D in data:
# Update the Bayes' rule numerator for each model.
prob = {M: prob[M] * likelihood(D, M) for M in prob}
# Calculate the Bayes' rule denominator.
norm = sum(prob.values())
# Calculate the posterior probabilities for each model.
prob = {M: prob[M] / norm for M in prob}
history.append(('D={}'.format(D), prob))
# Print our learning history.
index, rows = zip(*history)
IPython.display.display(pd.DataFrame(list(rows), index=index).round(3))
Learn(prior, likelihood, 't-shirt', 't-shirt')

https://commons.wikimedia.org/wiki/File:Dice_(typical_role_playing_game_dice).jpg
.jpg){kind=link}
EXERCISE: Suppose someone rolls 6, 4, 5 on a dice without telling you whether it has 4, 6, 8, 12, or 20 sides.
What is your intuition about the true number of sides based on the rolls?
Identify the models (hypotheses) and data in this problem.
Define your priors assuming that each model is equally likely.
Define a likelihood function assuming that each dice is fair.
Use the
Learnfunction to estimate the posterior probability for the number of sides after each roll.
We can be sure the dice is not 4-sided (because of the rolls > 4) and guess that it is unlikely to be 12 or 20 sided (since the largest roll is a 6).
The models in this problem correspond to the number of sides on the dice: 4, 6, 8, 12, 20.
The data in this problem are the dice rolls: 6, 4, 5.
Define the prior assuming that each model is equally likely:
prior = {4: 0.2, 6: 0.2, 8: 0.2, 12: 0.2, 20: 0.2}
Define the likelihood assuming that each dice is fair:
def likelihood(D, M):
if D <= M:
return 1.0 / M
else:
return 0.0
Finally, put the pieces together to estimate the posterior probability of each model after each roll:
Learn(prior, likelihood, 6, 4, 5)
Somewhat surprisingly, this toy problem has a practical application with historical significance!
Imagine a factory that has made \(N\) items, each with a serial number 1–\(N\). If you randomly select items and read their serial numbers, the problem of estimating \(N\) is analogous to our dice problem, but with many more models to consider. This approach was successfully used in World-War II by the Allied Forces to estimate the production rate of German tanks at a time when most academic statisticians rejected Bayesian methods.
For more historical perspective on the development of Bayesian methods (and many obstacles along the way), read the entertaining book The Theory That Would Not Die.
The discrete examples above can be solved exactly, but this is not true in general. The challenge is to calculate the evidence, \(P(D\mid M\)), in the Bayes’ rule denominator, as the marginalization integral:
With careful choices of the prior and likelihood function, this integral can be performed analytically. However, for most practical work, an approximate numerical approach is required. Popular methods include Markov-Chain Monte Carlo and Variational Inference, which we will meet soon.
What Priors Should I Use?#
The choice of priors is necessarily subjective and sometimes contentious, but keep the following general guidelines in mind:
Inferences on data from an informative experiment are not very sensitive to your choice of priors.
If your (posterior) results are sensitive to your choice of priors you need more (or better) data.
For a visual demonstration of these guidelines, the following function performs exact inference for a common task: you make a number of observations and count how many pass some predefined test, and want to infer the fraction \(0\le \theta\le 1\) that pass. This applies to questions like:
What fraction of galaxies contain a supermassive black hole?
What fraction of Higgs candidate decays are due to background?
What fraction of of my nanowires are superconducting?
For our prior, \(P(\theta)\), we use the beta distribution which is specified by hyperparameters \(a\) and \(b\):
where \(\Gamma\) is the gamma function related to the factorial \(\Gamma(n) = (n-1)!\)
def binomial_learn(prior_a, prior_b, n_obs, n_pass):
theta = np.linspace(0, 1, 100)
# Calculate and plot the prior on theta.
prior = scipy.stats.beta(prior_a, prior_b)
plt.fill_between(theta, prior.pdf(theta), alpha=0.25)
plt.plot(theta, prior.pdf(theta), label='Prior')
# Calculate and plot the likelihood of the fixed data given any theta.
likelihood = scipy.stats.binom.pmf(n_pass, n_obs, theta)
plt.plot(theta, likelihood, 'k:', label='Likelihood')
# Calculate and plot the posterior on theta given the observed data.
posterior = scipy.stats.beta(prior_a + n_pass, prior_b + n_obs - n_pass)
plt.fill_between(theta, posterior.pdf(theta), alpha=0.25)
plt.plot(theta, posterior.pdf(theta), label='Posterior')
# Plot cosmetics.
plt.legend(bbox_to_anchor=(0., 1.02, 1., .102), loc=3,
ncol=3, mode="expand", borderaxespad=0., fontsize='large')
plt.ylim(0, None)
plt.xlim(theta[0], theta[-1])
plt.xlabel('Pass fraction $\\theta$')
EXERCISE:
Q1: Think of a question in your research area where this inference problem applies.
Q2: Infer \(\theta\) from 2 observations with 1 passing, using hyperparameters \((a=1,b=1)\).
Explain why the posterior is reasonable given the observed data.
What values of \(\theta\) are absolutely ruled out by this data? Does this make sense?
How are the three quantities plotted normalized?
Q3: Infer \(\theta\) from the same 2 observations with 1 passing, using instead \((a=10,b=5)\).
Is the posterior still reasonable given the observed data? Explain your reasoning.
How might you choose between these two subjective priors?
Q4: Use each of the priors above with different data: 100 trials with 60 passing.
How does the relative importance of the prior and likelihood change with better data?
Why are the likelihood values so much smaller now?
binomial_learn(1, 1, 2, 1)
The posterior peaks at the mean observed pass rate, 1/2, which is reasonable. It is very broad because we have only made two observations.
Values of 0 and 1 are absolutely ruled out, which makes sense since we have already observed 1 pass and 1 no pass.
The prior and posterior are probability densities normalized over \(\theta\), so their area in the plot is 1. The likelihood is normalized over all possible data, so does not have area of 1 in this plot.
binomial_learn(5, 10, 2, 1)
The posterior now peaks away from the mean observed pass rate of 1/2. This is reasonable if we believe our prior information since, with relatively uninformative data, Bayes’ rule tells us that it should dominate our knowledge of \(\theta\). On the other hand, if we cannot justify why this prior is more believable than the earlier flat prior, then we must conclude that the value of \(\theta\) is unknown and that our data has not helped.
If a previous experiment with 13 observations found 4 passing, then our new prior would be very reasonable. However, if this process has never been observed and we have no theoretical prejudice, then the original flat prior would be reasonable.
binomial_learn(1, 1, 100, 60)
binomial_learn(5, 10, 100, 60)
With more data, the prior has much less influence. This is always the regime you want to be in.
The likelihood values are larger because there are many more possible outcomes (pass or not) with more observations, so any one outcome becomes relatively less likely. (Recall that the likelihood is normalized over data outcomes, not \(\theta\)).
You are hopefully convinced now that your choice of priors is mostly a non-issue if you have good data. However, you still need to make a choice, so here are some practical guidelines:
A “missing” prior, \(P(\Theta\mid M) = 1\), is still a prior but not necessarily a “natural” choice or a “safe default”. It is often not even normalizable, although you can finesse this problem with good enough data.
The prior on a parameter you care about usually summarizes previous measurements, assuming that you trust them but you are doing a better experiment. In this case, your likelihood measures the information provided by your data alone, and the posterior provides the new “world average”.
The prior on a nuisance parameter (which you need for technical reasons but are not interesting in measuring) should be set conservatively (restrict as little as possible, to minimize the influence on the posterior) and in different ways (compare posteriors with different priors to estimate systematic uncertainty).
If you really have no information on which to base a prior, learn about uninformative priors, but don’t be fooled by their apparent objectivity.
If being able to calculate your evidence integral analytically is especially important, look into conjugate priors, but don’t be surprised if this forces you to adopt an oversimplified model. The binomial example above is one of the rare cases where this works out.
Always state your priors (in your code, papers, talks, etc), even when they don’t matter much.
In practical situations, sometimes the choice of prior is taken as part of the systematic uncertainty on a measurement.
So, Why Isn’t Everyone a Bayesian?#
The answer is more complicated than this, but two primary reasons are often cited:
The calculations needed for Bayesian statistics can be overwhelming for practical applications. However, this is becoming increasing manageable with modern computers. Also, the advent of numerical methods for approximate inference, especially Markov chain Monte Carlo (MCMC) the we will introduce in the next lecture, have tranformed probabilstic data inference.
The structure requires a prior distribution (the “prior”) on the parameter of interest. If you use a different prior you will obtain different results and this “lack of objectivity” makes some people uncomfortable. However, we showed how some problems with sufficiant data can be relatively insensitive to choice of prior.
Acknowledgments#
Initial version: Mark Neubauer
© Copyright 2023